Implementing the in-Mapper Combiner for Performance Gains in Hadoop
By DB Tsai and Jenny Thompson. This article is also published in the blog of my company, Alpine Data Labs.
Before we start the article, let’s show you the benchmark first.
In the Alpine development team, we are always looking for ways to improve the efficiency of our algorithms. One of the most widely applicable and effective fixes we found was to implement the in-mapper combiner design pattern in our hadoop based algorithms. This can dramatically cut the amount of data transmitted across the network, and speed up the algorithm by 20%-50%.
For example, to implement the C4.5 decision tree algorithm we need to compute the information gain, which is essentially just counting all different combinations of independent and dependent variables; as a result, aggregating the result in mapper instead of emitting all of them for each row greatly increases performance. We also use this technique for our naive Bayes classifier, linear regression, and correlation operators.
A high level description and pseudo-code example can be found in Data-Intensive Text Processing with MapReduce by Jimmy Lin and Chris Dyer, 2010. It has been used in several MapReduce apps; for example, pig 0.10+ does this automatically. However, there are currently no ready-to-use concrete examples to be found online. Here we will present a step-by-step example with code, a word-count use-case and benchmarking.
An in-mapper combiner is much more efficient than a traditional combiner because it continually aggregates the data. As soon as it receives two values with the same key it combines them and stores the resulting key-value pair in a HashMap. However, if there are too many distinct keys, it may run out of memory. To avoid this problem, we use Least Recently Used (LRU) caching.
For each incoming key-value pair, we either add it as a new entry in the HashMap, or combine it with the existing entry for that key. If the HashMap grows bigger than the cache capacity, then the least recently used key-value pair will write to the context, and then there will be space in HashMap to store the new incoming key. Finally, in the cleanup method, any remaining entries are written to the context.
In contrast, when a mapper with a traditional combiner (the mini-reducer) emits the key-value pair, they are collected in the memory buffer and then the combiner aggregates a batch of these key-value pairs before sending them to the reducer. The drawbacks of this approach are
- The execution of combiner is not guaranteed; so MapReduce jobs cannot depend on the combiner execution.
- Hadoop may store the key-value pairs in local filesystem, and run the combiner later which will cause expensive disk IO.
- A combiner only combines data in the same buffer. Thus, we may still generate a lot of network traffic during the shuffle phase even if most of the keys from a single mapper are the same. To see this, consider the word count example, assuming that buffer size is 3, and we have <key, value> = <Stanford, 3>, <Berkeley, 1>, <Stanford, 7>, <Berkeley, 7>, and <Stanford, 2> emitted from one mapper. The first three items will be in one buffer, and last two will be in the the other buffer; as a result, the combiner will emit <Stanford, 10>, <Berkeley, 1>, <Berkeley, 7>, <Stanford, 2>. If we use in-mapper combiner, we will get <Stanford, 12>, <Berkeley, 8>.
Here is the implementation of in-mapper combiner using LRU cache that we use:
public class InMapperCombiner {
private static final int DEFAULT_CAPACITY = 8388608;
private static final int DEFAULT_INITIAL_CAPACITY = 65536;
private static final float DEFAULT_LOAD_FACTOR = .75F;
private final int maxCacheCapacity;
private final Map<KEY, VALUE> lruCache;
private CombiningFunction combiningFunction;
private Mapper.Context context;
public InMapperCombiner(int cacheCapacity, CombiningFunction combiningFunction, int initialCapacity, float loadFactor) {
this.combiningFunction = combiningFunction;
this.maxCacheCapacity = cacheCapacity;
lruCache = new LinkedHashMap<KEY, VALUE>(initialCapacity, loadFactor, true) {
@Override
@SuppressWarnings("unchecked")
protected boolean removeEldestEntry(Map.Entry<KEY, VALUE> eldest) {
boolean isFull = size() > maxCacheCapacity;
if (isFull) {
try {
// If the cache is full, emit the eldest key value pair to the reducer, and delete them from cache
context.write(eldest.getKey(), eldest.getValue());
} catch (IOException ex) {
throw new UncheckedIOException(ex);
} catch (InterruptedException ex) {
throw new UncheckedInterruptedException(ex);
}
}
return isFull;
}
};
}
public InMapperCombiner() {
this(DEFAULT_CAPACITY, null, DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public InMapperCombiner(int cacheCapacity) {
this(cacheCapacity, null, DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public InMapperCombiner(CombiningFunction combiningFunction) {
this(DEFAULT_CAPACITY, combiningFunction, 512, .75F);
}
public InMapperCombiner(int cacheCapacity, CombiningFunction combiningFunction) {
this(cacheCapacity, combiningFunction, 512, .75F);
}
public void setCombiningFunction(CombiningFunction combiningFunction) {
this.combiningFunction = combiningFunction;
}
@SuppressWarnings("unchecked")
public void write(KEY key, VALUE value, Mapper.Context context) throws InterruptedException, IOException {
/**
* In Hadoop, context.write(key, value) should have a new copy of key and value in context.write().
* This is because lots of time, people use
* private final static LongWritable one = new LongWritable(1);
* in the mapper class as global variable, and we don't want to reference to it in the LRU cache
* which may cause unexpected result. As a result, we will clone the key and value objects.
* */
Configuration conf = context.getConfiguration();
key = WritableUtils.clone(key, conf);
value = WritableUtils.clone(value, conf);
this.context = context;
if (combiningFunction != null) {
try {
if (!lruCache.containsKey(key)) {
lruCache.put(key, value);
} else {
lruCache.put(key, combiningFunction.combine(lruCache.get(key), value));
}
} catch (UncheckedIOException ex) {
throw new IOException(ex);
} catch (UncheckedInterruptedException ex) {
throw new InterruptedException(ex.toString());
}
} else {
context.write(key, value);
}
}
@SuppressWarnings("unchecked")
public void flush(Mapper.Context context) throws IOException, InterruptedException {
// Emit the key-value pair from the LRU cache.
if (!lruCache.isEmpty()) {
for (Map.Entry<KEY, VALUE> item : lruCache.entrySet()) {
context.write(item.getKey(), item.getValue());
}
}
lruCache.clear();
}
private static class UncheckedIOException extends java.lang.RuntimeException {
public UncheckedIOException(Throwable throwable) {
super(throwable);
}
}
private static class UncheckedInterruptedException extends java.lang.RuntimeException {
public UncheckedInterruptedException(Throwable throwable) {
super(throwable);
}
}
}
The api is pretty simple, just change context.write to combiner.write, and remember to flush the cache in the clean up method.
Here is the example of implementing hadoop classical word count mapper with in-mapper combiner:
public static class WordCountMapperWithInMapperCombiner extends Mapper<LongWritable, Text, Text, LongWritable> {
private final static LongWritable one = new LongWritable(1);
private final Text word = new Text();
private final InMapperCombiner combiner = new InMapperCombiner<Text, LongWritable>(
new CombiningFunction() {
@Override
public LongWritable combine(LongWritable value1, LongWritable value2) {
value1.set(value1.get() + value2.get());
return value1;
}
}
);
@Override
@SuppressWarnings("unchecked")
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = getCleanLine(value.toString());
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
combiner.write(word, one, context);
}
}
@Override
protected void cleanup(Mapper.Context context) throws IOException, InterruptedException {
combiner.flush(context);
}
}
The source code of this example project can be downloaded at hadoop-word-count.
After you clone the project, you can build the jar file by
./sbt package
you will get mapreduce/target/mapreduce-0.1.jar.
Now, let’s download English wikipedia dataset (the size of the 2 October 2013 dump is approximately 9.5 GB compressed, 44 GB uncompressed). Since the file is in XML format, we need to convert it to plain text in order to run MapReduce word count. We’ll use WikiExtractor.py to perform the conversion.
The following command will download WikiExtractor.py, wikipedia dataset, and then convert it to plain text. It may take couple hours depending on your network and machine.
wget https://raw.github.com/bwbaugh/wikipedia-extractor/master/WikiExtractor.py
wget http://download.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2
bzcat enwiki-latest-pages-articles.xml.bz2 | python WikiExtractor.py -cb 100M -o extracted
find extracted -name '*bz2' -exec bunzip2 -c {} \; > enwiki.txt
rm -rf extracted
Upload enwiki.txt to HDFS:
hadoop dfs -put enwiki.txt /users/USER_NAME/
Run Word Count without any optimization:
hadoop jar mapreduce-0.1.jar com.dbtsai.hadoop.main.WordCount /users/USER_NAME/enwiki.txt /users/USER_NAME/WordCountResult
Run Word Count with typical combiner:
hadoop jar mapreduce-0.1.jar com.dbtsai.hadoop.main.WordCountWithCombiner /users/USER_NAME/enwiki.txt /users/USER_NAME/WordCountWithCombinerResult
Run Word Count with in-mapper combiner:
hadoop jar mapreduce-0.1.jar com.dbtsai.hadoop.main.WordCountWithInMapperCombiner /users/USER_NAME/enwiki.txt /users/USER_NAME/WordCountWithInMapperCombinerResult
Let’s compare stanford or berkeley has higher counts by:
hadoop dfs -cat /users/USER_NAME/WordCountWithInMapperCombinerResult | grep stanford hadoop dfs -cat /users/USER_NAME/WordCountWithInMapperCombinerResult | grep berkeley
Which one will win???
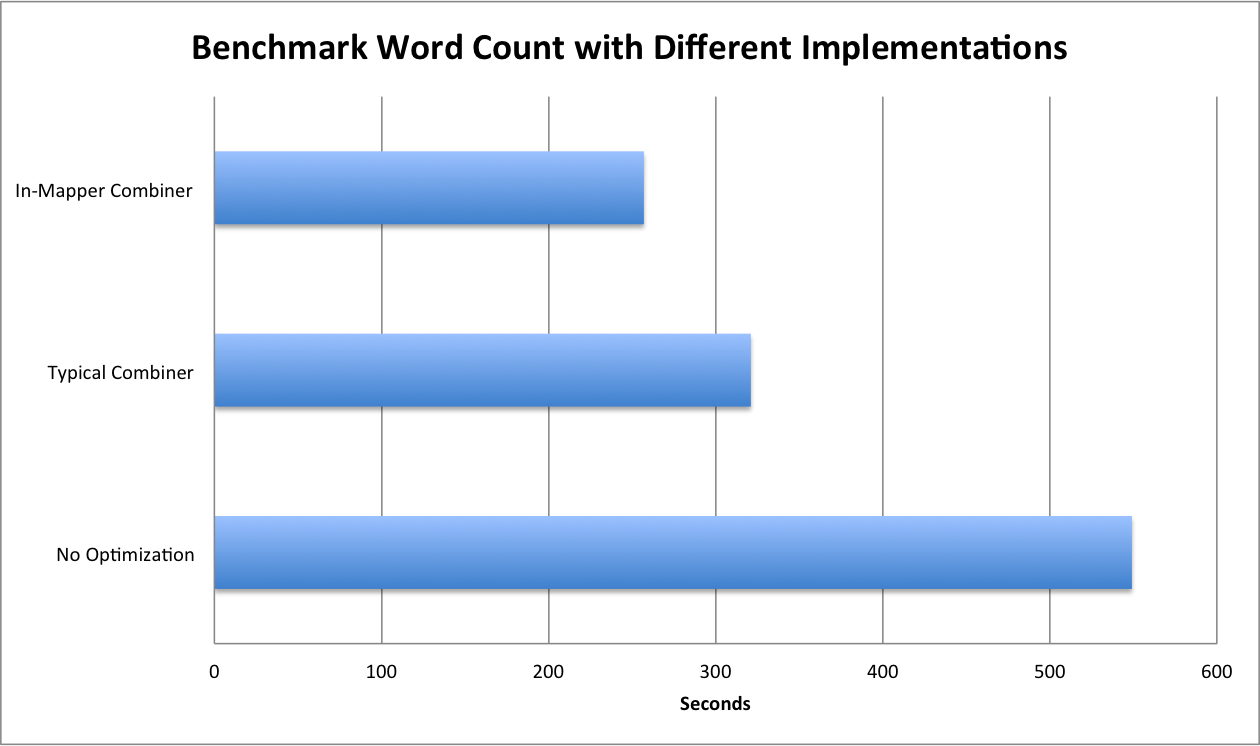
Finally, let’s compare the performance. We tested it on a three nodes CDH4 clusters with Gigabit Network.
- Word Count: 9mins, 9sec
- Word Count with Combiner: 5mins, 21sec
- Word Count with in-Mapper Combiner: 4mins, 17 sec
You can see that the typical combiner is 1.71 times faster than the word count without any optimization. The in-mapper combiner is 1.25 times faster than typical combiner. Depending on different application and input dataset distribution, we see the performance gain varying from 20% to 50% between typical combiner and in-mapper combiner.
If you study the job detail, you will find that with in-mapper combiner, the Map output records will be significantly decreased compared with typical combiner; as a result, the Reduce shuffle bytes will become smaller as well. Those improve the performance.
BIG DATA · COMPUTER · HADOOP · JAVA · PROGRAMING
English