Hadoop M/R to implement “People You Might Know” friendship recommendation
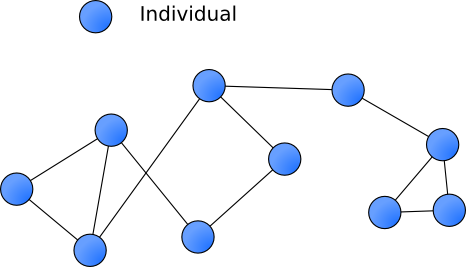
The best friendship recommendations often come from friends. The key idea is that if two people have a lot of mutual friends, but they are not friends, then the system should recommend them to be connected to each other.
Let’s assume that the friendships are undirected: if A is a friend of B then B is also a friend of A. This is the most common friendship system used in Facebook, Google+, Linkedin, and several social networks. It’s not difficult to extend it to directed friendship system used in twitter; however, we’ll focus on the undirected case throughout this post.
The context of this article is modified into an exercise by Dr. Matthew for his students, you may want to check it out!
The input data will contain the adjacency list and has multiple lines in the format of
0 1,2,3
1 0,2,3,4,5
2 0,1,4
3 0,1,4
4 1,2,3
5 1,6
6 5
In the graph, you can see user 0 is not friends of user 4, and 5, but user 0 and user 4 have mutual friends 1, 2, and 3; user 0 and user 5 have mutual friend 1. As a result, we would like to recommend user 4 and 5 as friends of user 0.
The output recommended friends will be given in the following format.
0 4 (3: [3, 1, 2]),5 (1: [1])
1 6 (1: [5])
2 3 (3: [1, 4, 0]),5 (1: [1])
3 2 (3: [4, 0, 1]),5 (1: [1])
4 0 (3: [2, 3, 1]),5 (1: [1])
5 0 (1: [1]),2 (1: [1]),3 (1: [1]),4 (1: [1])
6 1 (1: [5])
Now, let’s fit this problem into single M/R job. User 0 has friends, 1, 2, and 3; as a result, the pair of <1, 2>, <2, 1>, <2, 3>, <3, 2>, <1, 3>, and <3, 1> have mutual friend of user 0. As a result, we can emit <key, value> = <1, r=2; m=0>, <2, r=1; m=0>, <2, r=3; m=0>…, where r means recommended friend, and m means mutual friend. We can aggregate the result in the reduce phase, and calculate how many mutual friends they have between a user and recommended user. However, this approach will cause a problem. What if user A and the recommended user B are already friends? In order to overcome this problem, we can add another attribute isFriend into the emitted value, and we just don’t recommend the friend if we know they are already friends in the reduce phase. In the following implementation, m = -1 is used when they are already friends instead of using extra field.
Define that fromUser is
Map phase
- Emit <fromUser, r=toUser; m=-1> for all toUser. Let’s say there are n toUser; then we’ll emit *n *records for describing that fromUser and toUser are already friends. Note that they are already friends between the emitted key, and r, so we set m as -1.
- Emit <toUser1, r=toUser2; m=fromUser> for all the possible combination of toUser1, and toUser2 from toUser, and they have mutual friend, fromUser. It will emit n(n – 1) records.
- Totally, there are n^2 emitted records in the map phase, where n is the number of friends
has.
Reduce phase,
- Just summing how many mutual friends they have between the key, and r in the value. If any of them has mutual friend -1, we don’t make the recommendation since they are already friends.
- Sort the result based on the number of mutual friends.
Because the emitted value is not primitive data type in hadoop, we have to customize a new writable type as the following code.
static public class FriendCountWritable implements Writable {
public Long user;
public Long mutualFriend;
public FriendCountWritable(Long user, Long mutualFriend) {
this.user = user;
this.mutualFriend = mutualFriend;
}
public FriendCountWritable() {
this(-1L, -1L);
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(user);
out.writeLong(mutualFriend);
}
@Override
public void readFields(DataInput in) throws IOException {
user = in.readLong();
mutualFriend = in.readLong();
}
@Override
public String toString() {
return " toUser: "
+ Long.toString(user) + " mutualFriend: "
+ Long.toString(mutualFriend);
}
}
The mapper can be implemented by
public static class Map extends Mapper<LongWritable, Text, LongWritable, FriendCountWritable> {
private Text word = new Text();
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line[] = value.toString().split("\t");
Long fromUser = Long.parseLong(line[0]);
List toUsers = new ArrayList();
if (line.length == 2) {
StringTokenizer tokenizer = new StringTokenizer(line[1], ",");
while (tokenizer.hasMoreTokens()) {
Long toUser = Long.parseLong(tokenizer.nextToken());
toUsers.add(toUser);
context.write(new LongWritable(fromUser),
new FriendCountWritable(toUser, -1L));
}
for (int i = 0; i < toUsers.size(); i++) {
for (int j = i + 1; j < toUsers.size(); j++) {
context.write(new LongWritable(toUsers.get(i)),
new FriendCountWritable((toUsers.get(j)), fromUser));
context.write(new LongWritable(toUsers.get(j)),
new FriendCountWritable((toUsers.get(i)), fromUser));
}
}
}
}
}
The reducer can be implemented by
public static class Reduce extends Reducer<LongWritable, FriendCountWritable, LongWritable, Text> {
@Override
public void reduce(LongWritable key, Iterable values, Context context)
throws IOException, InterruptedException {
// key is the recommended friend, and value is the list of mutual friends
final java.util.Map<Long, List> mutualFriends = new HashMap<Long, List>();
for (FriendCountWritable val : values) {
final Boolean isAlreadyFriend = (val.mutualFriend == -1);
final Long toUser = val.user;
final Long mutualFriend = val.mutualFriend;
if (mutualFriends.containsKey(toUser)) {
if (isAlreadyFriend) {
mutualFriends.put(toUser, null);
} else if (mutualFriends.get(toUser) != null) {
mutualFriends.get(toUser).add(mutualFriend);
}
} else {
if (!isAlreadyFriend) {
mutualFriends.put(toUser, new ArrayList() {
{
add(mutualFriend);
}
});
} else {
mutualFriends.put(toUser, null);
}
}
}
java.util.SortedMap<Long, List> sortedMutualFriends = new TreeMap<Long, List>(new Comparator() {
@Override
public int compare(Long key1, Long key2) {
Integer v1 = mutualFriends.get(key1).size();
Integer v2 = mutualFriends.get(key2).size();
if (v1 > v2) {
return -1;
} else if (v1.equals(v2) && key1 < key2) {
return -1;
} else {
return 1;
}
}
});
for (java.util.Map.Entry<Long, List> entry : mutualFriends.entrySet()) {
if (entry.getValue() != null) {
sortedMutualFriends.put(entry.getKey(), entry.getValue());
}
}
Integer i = 0;
String output = "";
for (java.util.Map.Entry<Long, List> entry : sortedMutualFriends.entrySet()) {
if (i == 0) {
output = entry.getKey().toString() + " (" + entry.getValue().size() + ": " + entry.getValue() + ")";
} else {
output += "," + entry.getKey().toString() + " (" + entry.getValue().size() + ": " + entry.getValue() + ")";
}
++i;
}
context.write(key, new Text(output));
}
}
where Comparator is used in TreeMap for sorting the output value in decreasing order of the number of mutual friends.
The full working code can be downloaded at M/R Friend Recommendation under Apache v2 Licence. I also want to provide a bigger data set from Stanford CS246 class, Mining Massive Data Sets at soc-LiveJournal1Adj.
BIG DATA · COMPUTER · HADOOP · PROGRAMING
English